目前有个需求,就是把所有sql转为mongo管道查询
知识点
在 MongoDB 中,allowDiskUse 选项应该作为聚合命令的一个选项,而不是聚合管道的一个阶段。allowDiskUse 选项用于允许聚合操作使用磁盘空间来临时存储数据(当聚合操作的数据集非常大,无法在内存中完全处理时)。
$group 阶段:
这个阶段按照 province 字段的值对数据进行分组。
对于每个分组(即每个省份),它会收集所有不同的 $sha1 字段值,并将它们放入一个集合(set)中,因为这个阶段使用了 $addToSet 累加器。由于集合(set)中的元素是唯一的,所以每个 $sha1 值只会被添加到集合中一次。
这个集合被存储在新的 cert_count 字段中,但实际上它包含了 $sha1 的值,而不是真正的“证书数量”。
$addFields 阶段:
这个阶段是对上一阶段输出文档的一个处理。
它使用了 $size 表达式来计算 cert_count 字段(实际上是一个集合)中的元素数量,并将结果仍然保存在 cert_count 字段中。
经过这个阶段后,cert_count 字段现在包含了每个省份中不同的 $sha1 值的数量。虽然名称还是 cert_count,但现在它实际上表示的是每个省份中不同 $sha1 值的数量,而不是直接的“证书数量”。
需求一:目前的需求是根据省份分组求唯一证书的数量,所以需要去重
原有sql
省:证书 分组统计
query = f"""
SELECT province, COUNT(DISTINCT(sha1)) AS cert_count
FROM {cls.table_name}
Group BY province
ORDER BY cert_count DESC
"""
去重前
db.cert_info.aggregate([
{
'$group': {
'_id': '$province',
'cert_count': {
'$sum': 1
}
}
},
{
'$sort': {
'cert_count': - 1
}
},
{
'$limit': 10
}
], {
allowDiskUse: true
})
结果
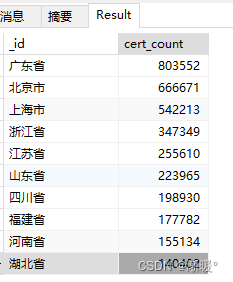
去重后
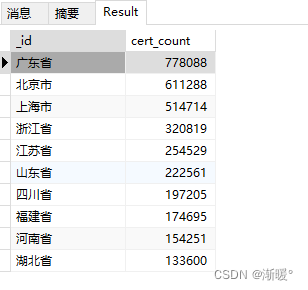
第一种写法:
db.cert_info.aggregate([
{
'$group': {
'_id': {
'province': '$province',
'sha1': '$sha1'
},
// 由于我们只需要去重计数,所以这里不需要额外的累加器
// 我们只是简单地按 province 和 sha1 组合进行分组
}
},
{
'$group': {
'_id': '$_id.province', // 按 province 重新分组
'cert_count': {
'$sum': 1 // 计算每个 province 的唯一 sha1 的数量
}
}
},
{
'$sort': {
'cert_count': -1 // 按证书数量降序排序
}
},
{
'$limit': 10 // 限制结果集大小为 10
}
], {
allowDiskUse: true // 允许聚合操作使用磁盘空间
});
结果
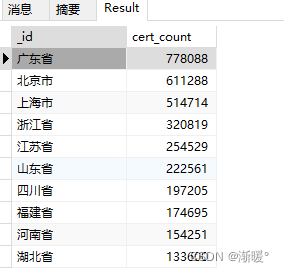
第二种写法:
db.cert_info.aggregate([
{
'$group': {
'_id': '$province',
'cert_count': {
'$addToSet': '$sha1'
}
}
},
{
'$addFields': {
'cert_count': {
'$size': '$cert_count'
}
}
},
{
'$sort': {
'cert_count': - 1
}
},
{
'$limit': 10
}
], {
allowDiskUse: true
})
查询结果
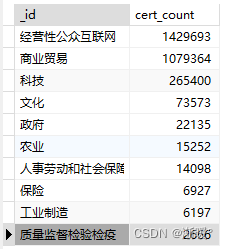
需求二:按照行业分组,统计唯一证书数量,过滤掉其他和未知的行业
原有sql
query = f"""
SELECT yb_industry, COUNT(DISTINCT(sha1)) AS cert_count
FROM {cls.table_name}
WHERE yb_industry NOT IN ['其他','未知']
Group BY yb_industry
ORDER BY cert_count DESC
"""
mongo
db.cert_info.aggregate([{
'$match': {
'yb_industry': {
'$nin': ['其他', '未知']
}
}
},
{
'$group': {
'_id': '$yb_industry',
'cert_count': {
'$addToSet': '$sha1'
}
}
},
{
'$addFields': {
'cert_count': {
'$size': '$cert_count'
}
}
},
{
'$sort': {
'cert_count': -1
}
},
{
'$limit': 10
}], {allowDiskUse: true})
再加个省份分组
province_pipeline = [
{
'$match': {
'domestic': True,
'yb_industry': {
'$nin': ['其他', '未知']
}
}
},
{
'$addFields': {
'province_temp': '$province'
}
},
{
'$group': {
'_id': {
'yb_industry': '$yb_industry',
'province': '$province_temp'
},
'sha1_set': {
'$addToSet': '$sha1'
}
}
},
{
'$addFields': {
'province': '$_id.province',
'cert_count': {
'$size': {
'$setUnion': ['$sha1_set', []]
}
}
}
},
{
'$sort': {
'cert_count': -1
}
},
{
'$project': {
'_id': 0,
'yb_industry': '$_id.yb_industry',
'province': '$_id.province',
'cert_count': 1
}
}
]
查询的时候按照省份过滤,取top10
# 使用filter函数过滤data列表
filtered_data = list(filter(lambda item: item['province'] == province, data))
top10_data = filtered_data[:10]
return Response(top10_data)
需求三:查询过期的证书
原有sql
SELECT province, COUNT(DISTINCT(sha1)) AS cert_count
FROM {cls.table_name}
WHERE end < NOW()
Group BY province
ORDER BY cert_count DESC
![[leetcode] 67. 二进制求和](https://img-blog.csdnimg.cn/direct/a36c1b59f2eb48eebd27dc7ba26116ca.png)